Essential volesti tutorial in R
This is a merge of a series of volesti tutorials presented in university courses and seminars in 2016-2018.
volesti is a C++ package (with an R interface) for computing estimations of volume of polytopes given by a set of points or linear inequalities or Minkowski sum of segments (zonotopes). There are two algorithms for volume estimation and algorithms for sampling, rounding and rotating polytopes.
We can download the R package from the CRAN webpage.
# first load the volesti library
library(volesti)
packageVersion("volesti")
You have access to the documentation of volesti functions like volume computation and sampling.
help("volume")
help("sample_points")
Let’s try our first volesti command to estimate the volume of a 3-dimensional cube \({-1\leq x_i \leq 1,x_i \in \mathbb R\ |\ i=1,2,3}\)
P <- GenCube(3,'H')
print(volume(P))
What is the exact volume of P? Did we obtain a good estimation?
Sampling
Sampling in the square.
library(ggplot2)
x1<-runif(1000, min = -1, max = 1)
x2<-runif(1000, min = -1, max = 1)
g<-ggplot(data.frame( x=x1, y=x2 )) + geom_point( aes(x=x, y=y))
g<-g+annotate("path",
x=cos(seq(0,2*pi,length.out=100)),
y=sin(seq(0,2*pi,length.out=100)),color="red")+coord_fixed()
plot(g)
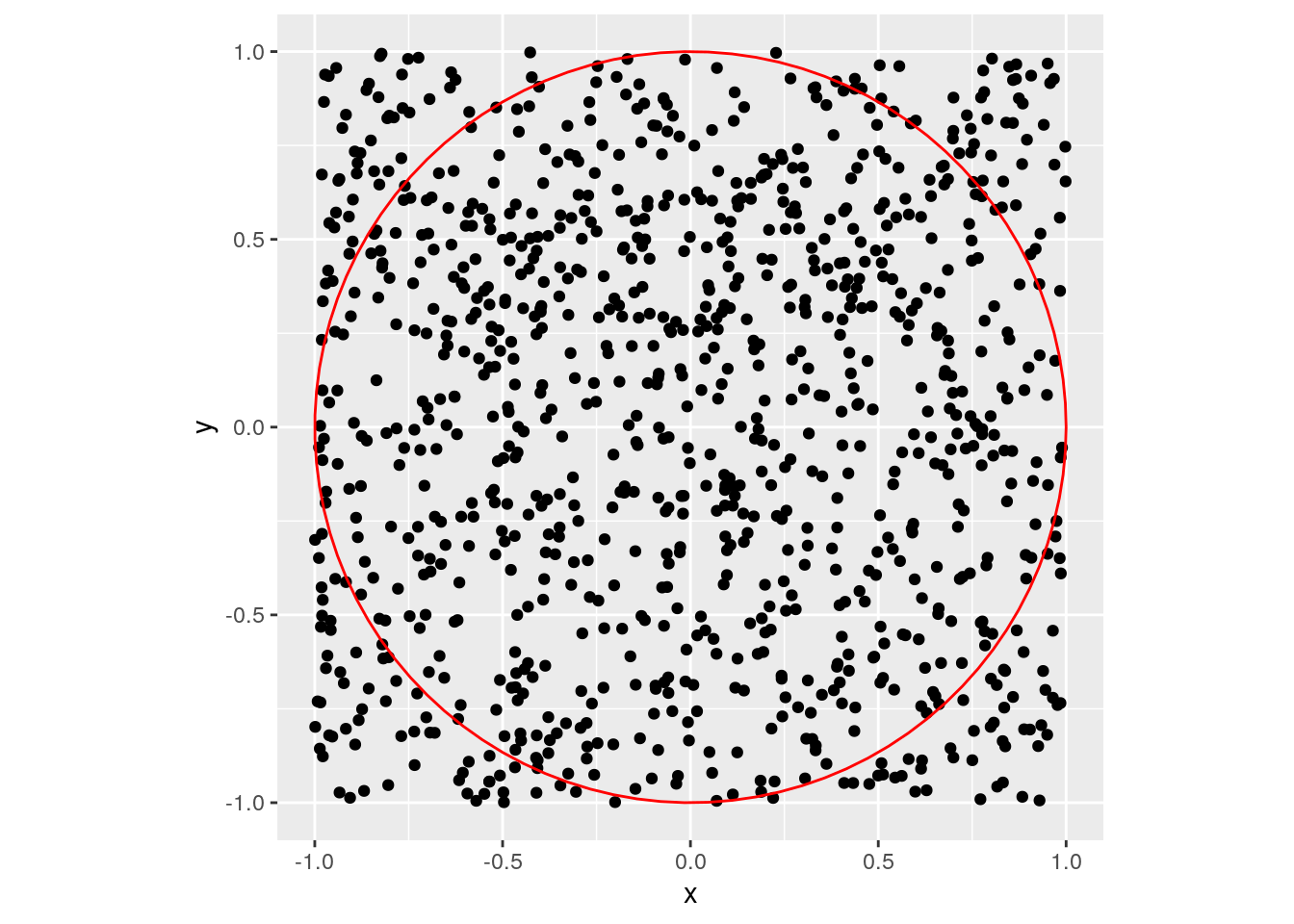
Can we estimate the volume of the red ball via sampling? Solution: rejection sampling. The following computation illustrates that this will fail in (not so) high dimensions.
# run in around 1 min
for (d in 2:20) {
num_of_points <- 100000
count_inside <- 0
points1 <- matrix(nrow=d, ncol=num_of_points)
for (i in 1:d) {
x <- runif(num_of_points, min = -1, max = 1)
for (j in 1:num_of_points) {
points1[i,j] <- x[j]
}
}
for (i in 1:num_of_points) {
if (norm(points1[,i], type="2") < 1) {
count_inside <- count_inside + 1
}
}
vol_estimation <- count_inside*2^d/num_of_points
vol_exact <- pi^(d/2)/gamma(d/2+1)
cat(d, vol_estimation, vol_exact, abs(vol_estimation- vol_exact)/
vol_exact, "\n")
}
## 2 3.14336 3.141593 0.0005625638
## 3 4.20192 4.18879 0.003134508
## 4 4.91808 4.934802 0.003388626
## 5 5.28128 5.263789 0.003322889
## 6 5.13216 5.167713 0.00687979
## 7 4.82304 4.724766 0.02079977
## 8 4.0192 4.058712 0.009735139
## 9 3.46624 3.298509 0.05085058
## 10 2.28352 2.550164 0.1045596
## 11 1.86368 1.884104 0.0108401
## 12 1.55648 1.335263 0.1656732
## 13 0.57344 0.9106288 0.3702813
## 14 0.32768 0.5992645 0.4531964
## 15 0.65536 0.3814433 0.718106
## 16 0 0.2353306 1
## 17 0 0.1409811 1
## 18 0 0.08214589 1
## 19 0 0.0466216 1
## 20 0 0.02580689 1
Sampling via random walks
volesti supports the following three types of random walks
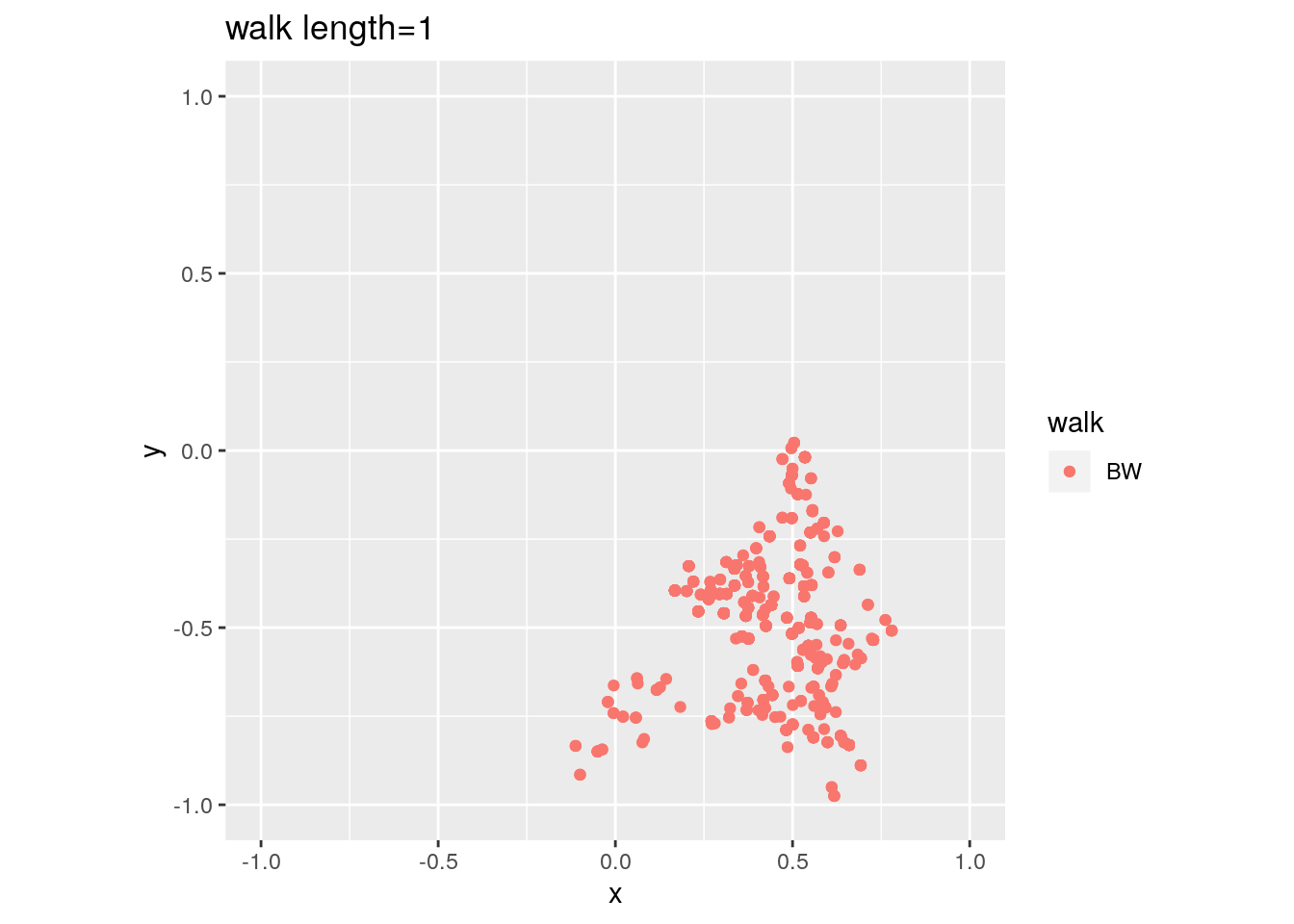
Ball walk (BW)
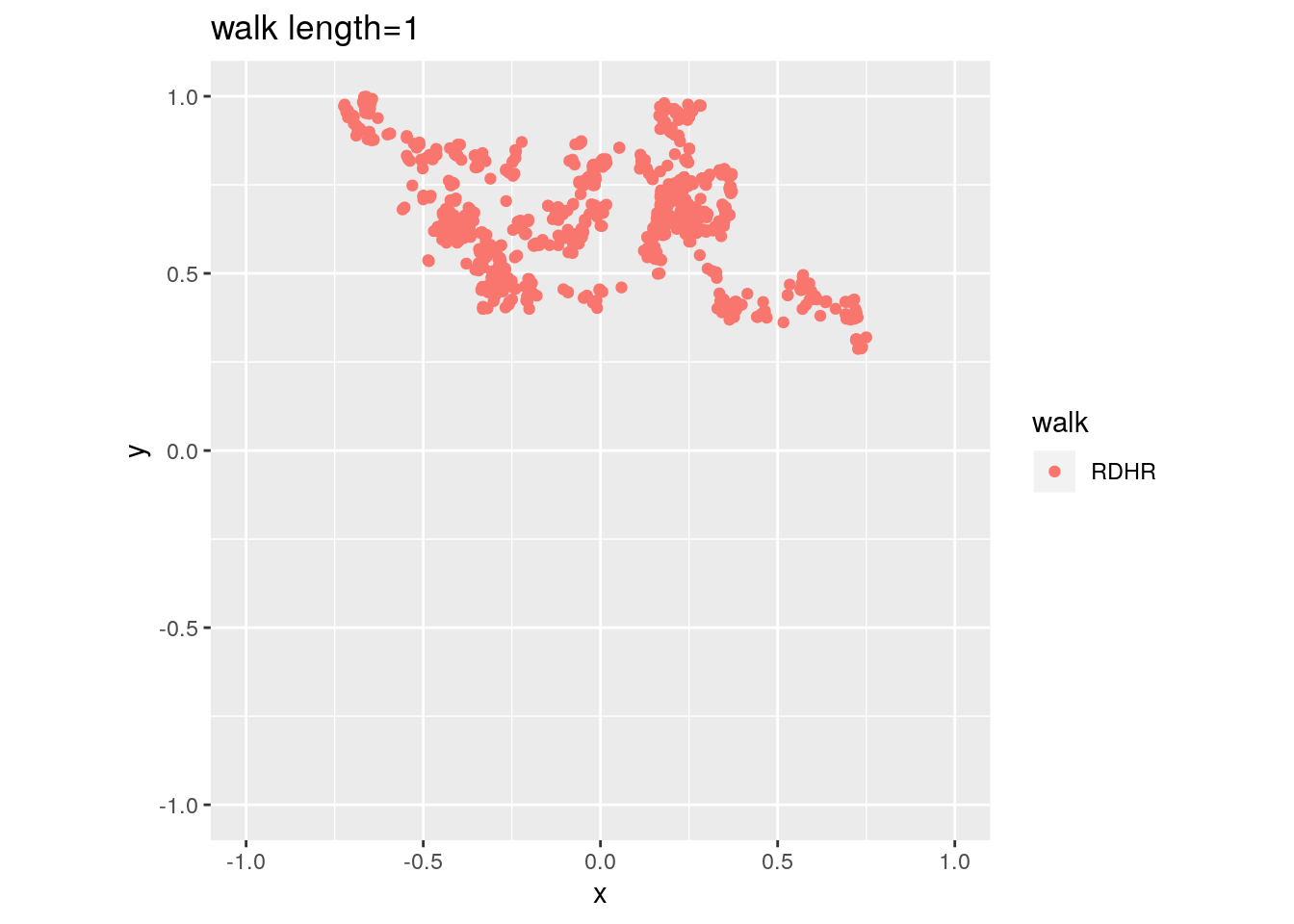
Random directions hit-and-run (RDHR)
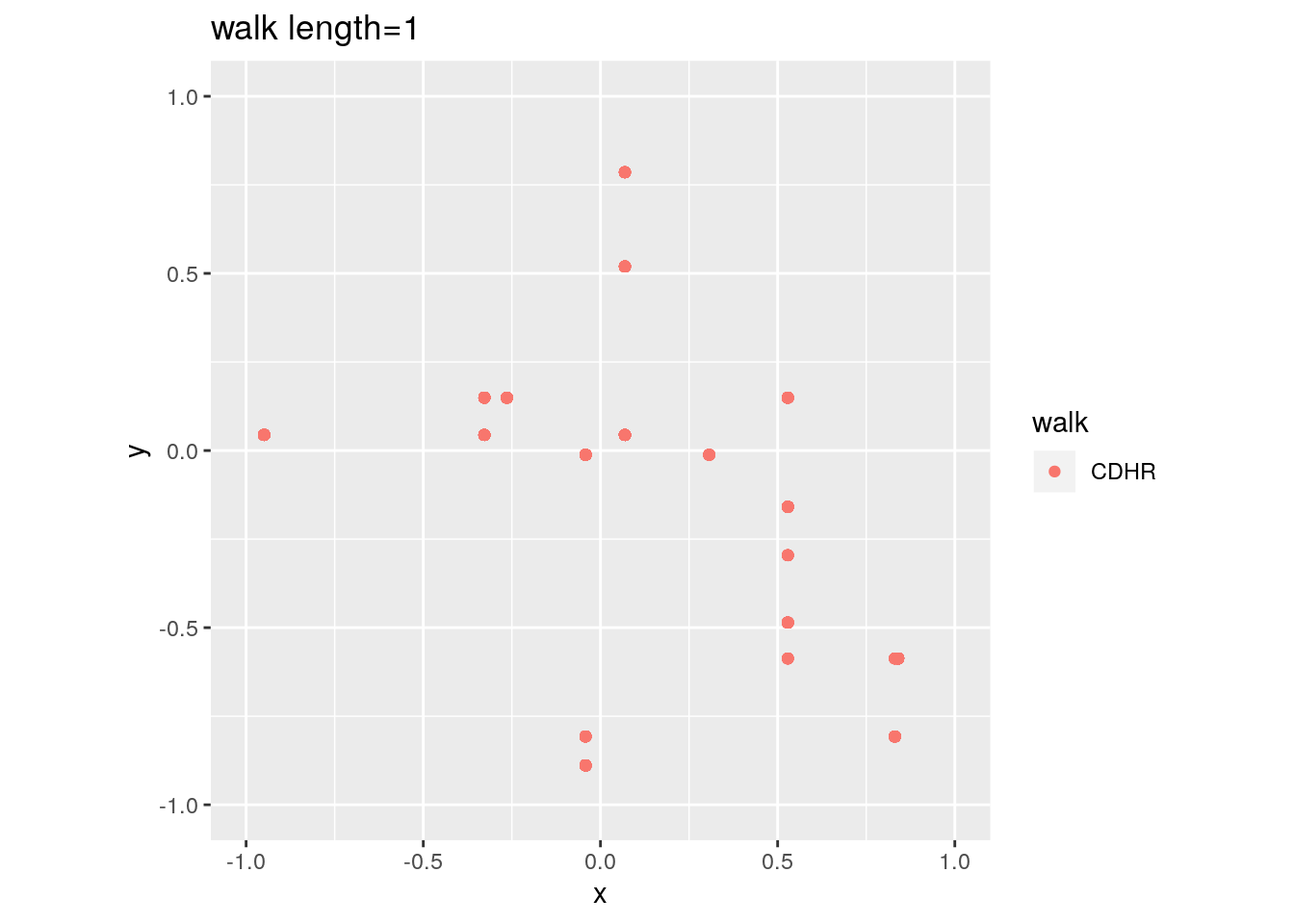
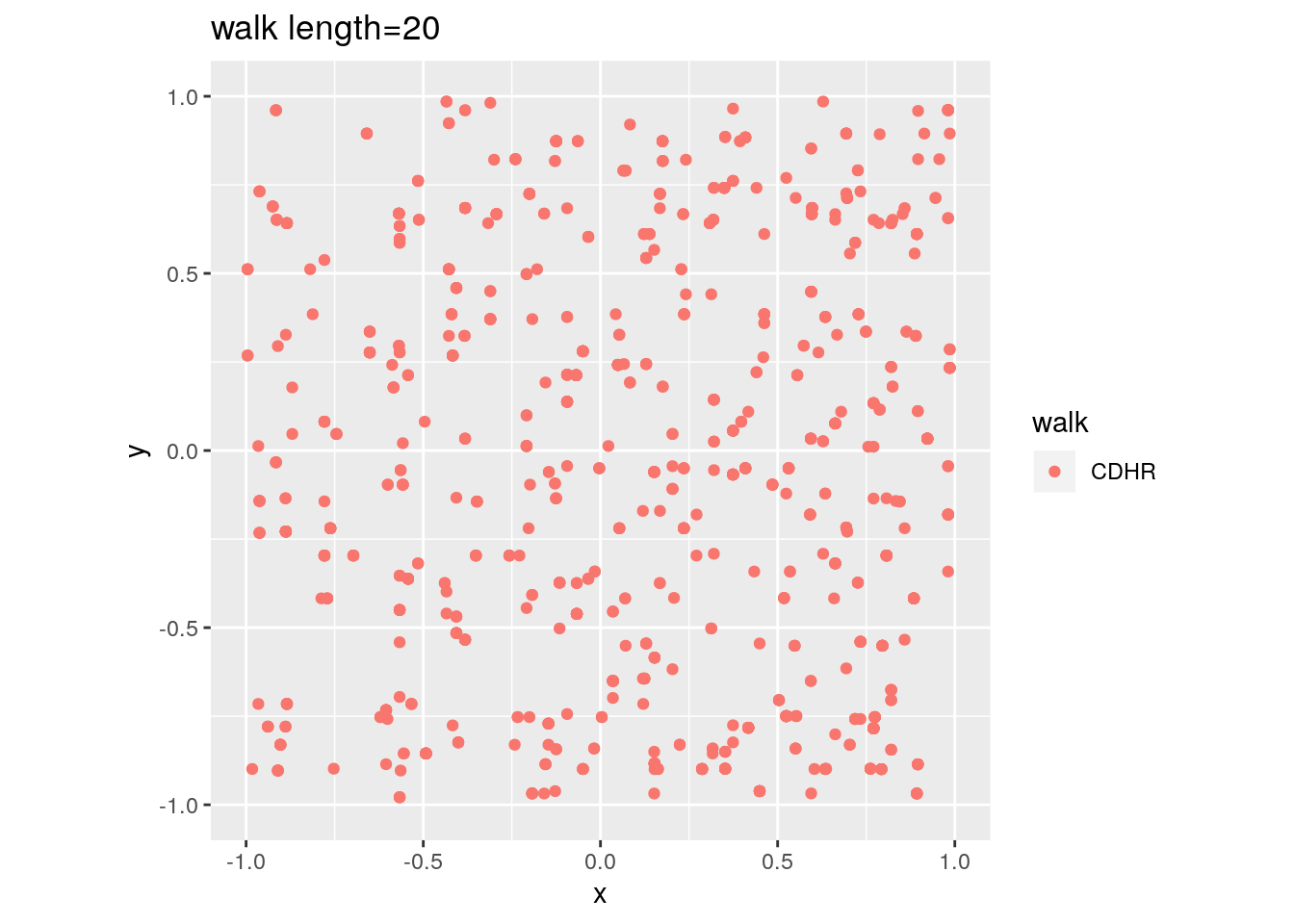
Coordinate directions hit-and-run (CDHR)
BW |
RDHR |
CDHR |
|---|---|---|
|
|
|
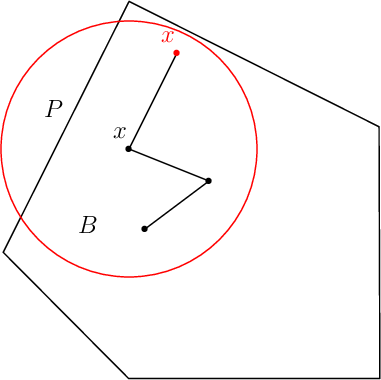
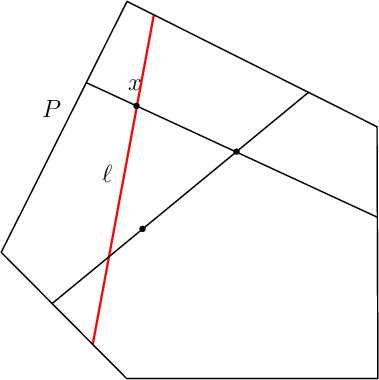
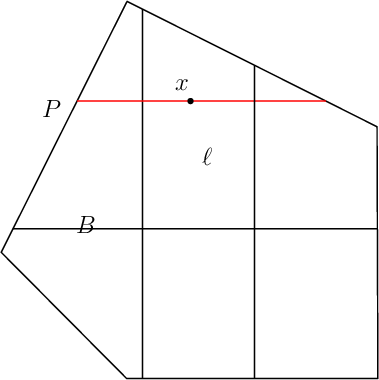
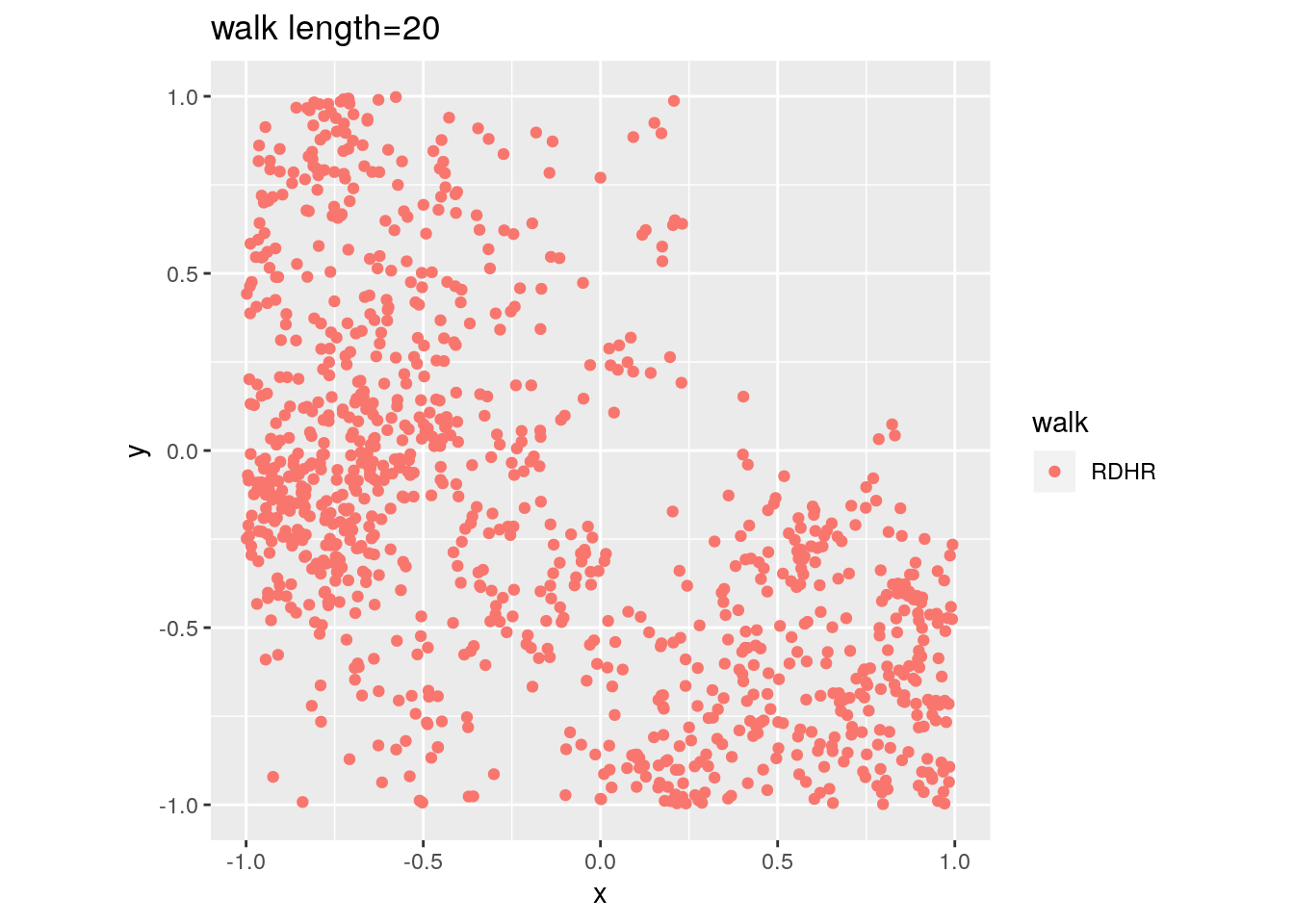
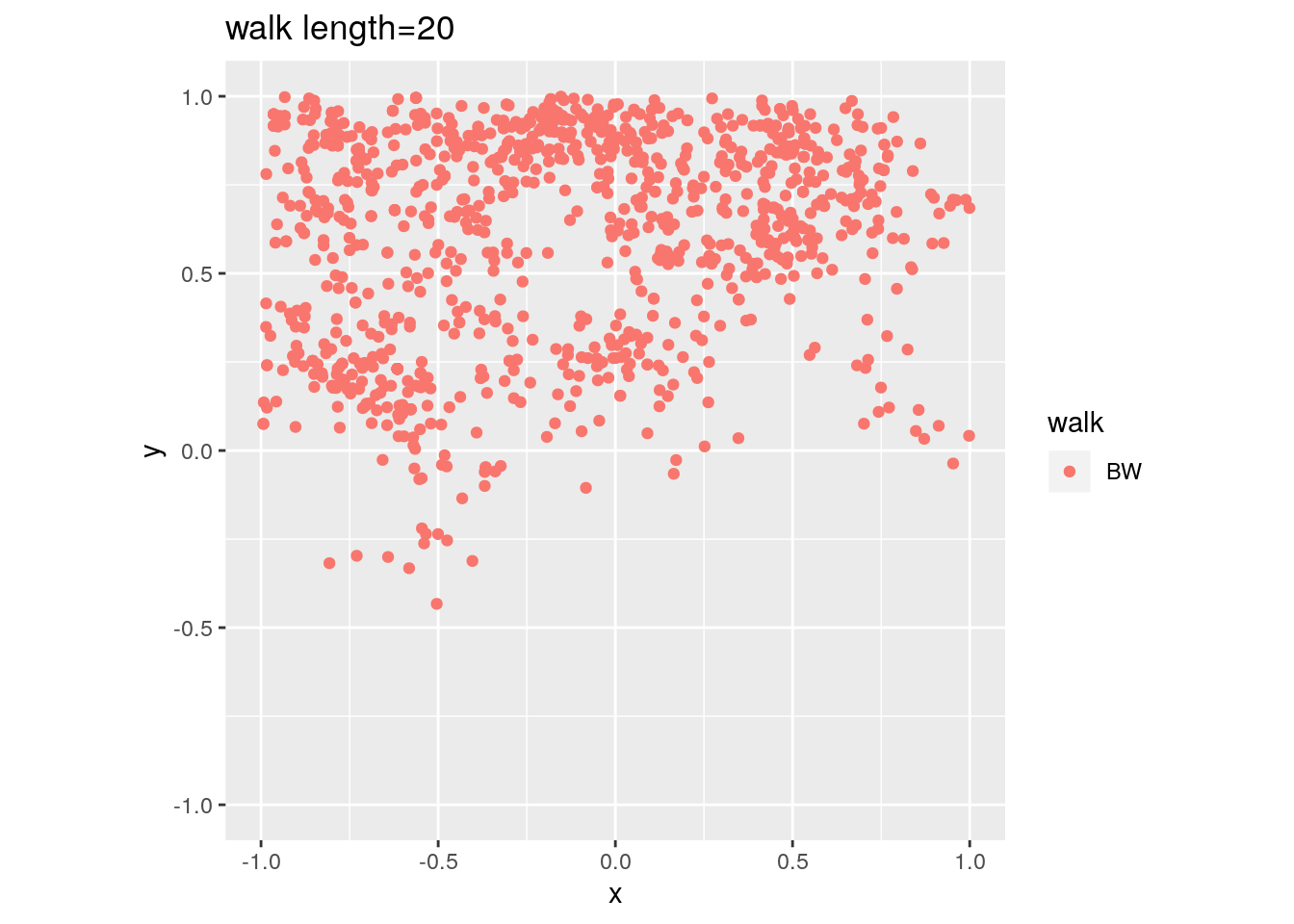
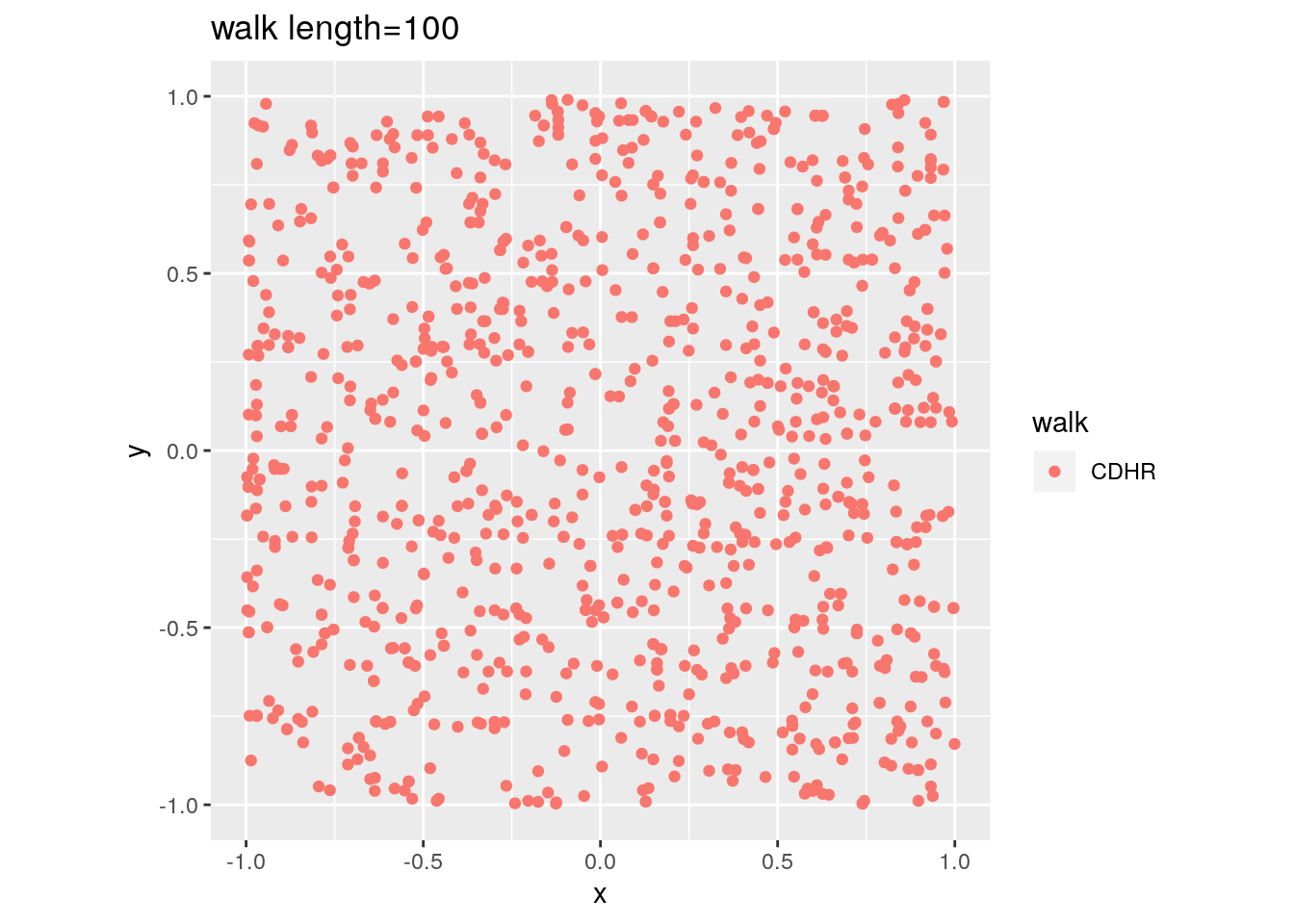
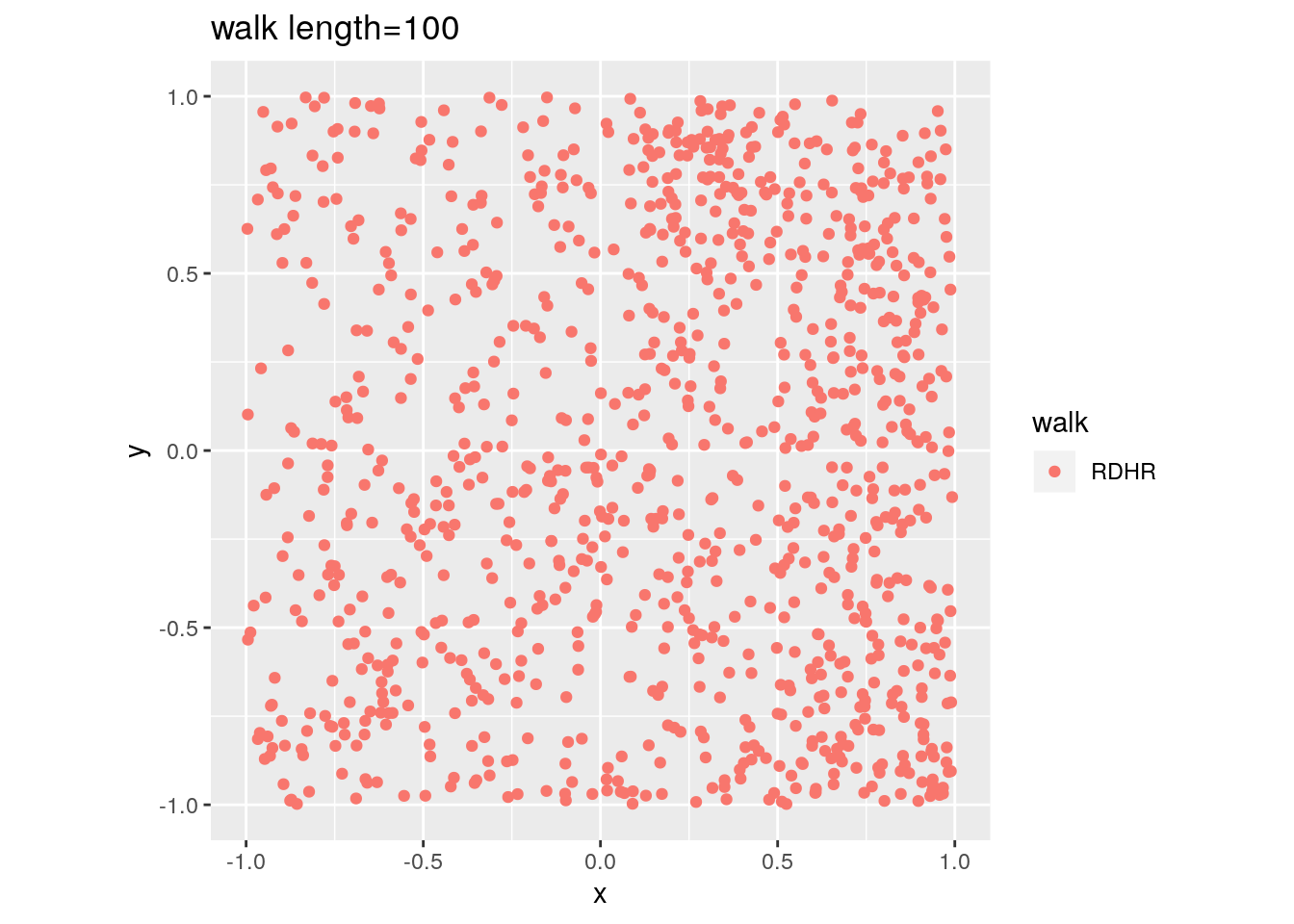
There are two important parameters cost per step and mixing time that affects the accuracy and performance of the walks. Below we illustrate this by choosing different walk steps for each walk while sampling on the 100-dimensional cube.
#run in few secs
library(ggplot2)
library(volesti)
for (step in c(1,20,100,150)){
for (walk in c("CDHR", "RDHR", "BW")){
P <- GenCube(100, 'H')
points1 <- sample_points(P, WalkType = walk, walk_step = step, N=1000)
g<-plot(ggplot(data.frame( x=points1[1,], y=points1[2,] )) +
geom_point( aes(x=x, y=y, color=walk)) + coord_fixed(xlim = c(-1,1),
ylim = c(-1,1)) + ggtitle(sprintf("walk length=%s", step, walk)))
}
}
CDHR |
RDHR |
BW |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
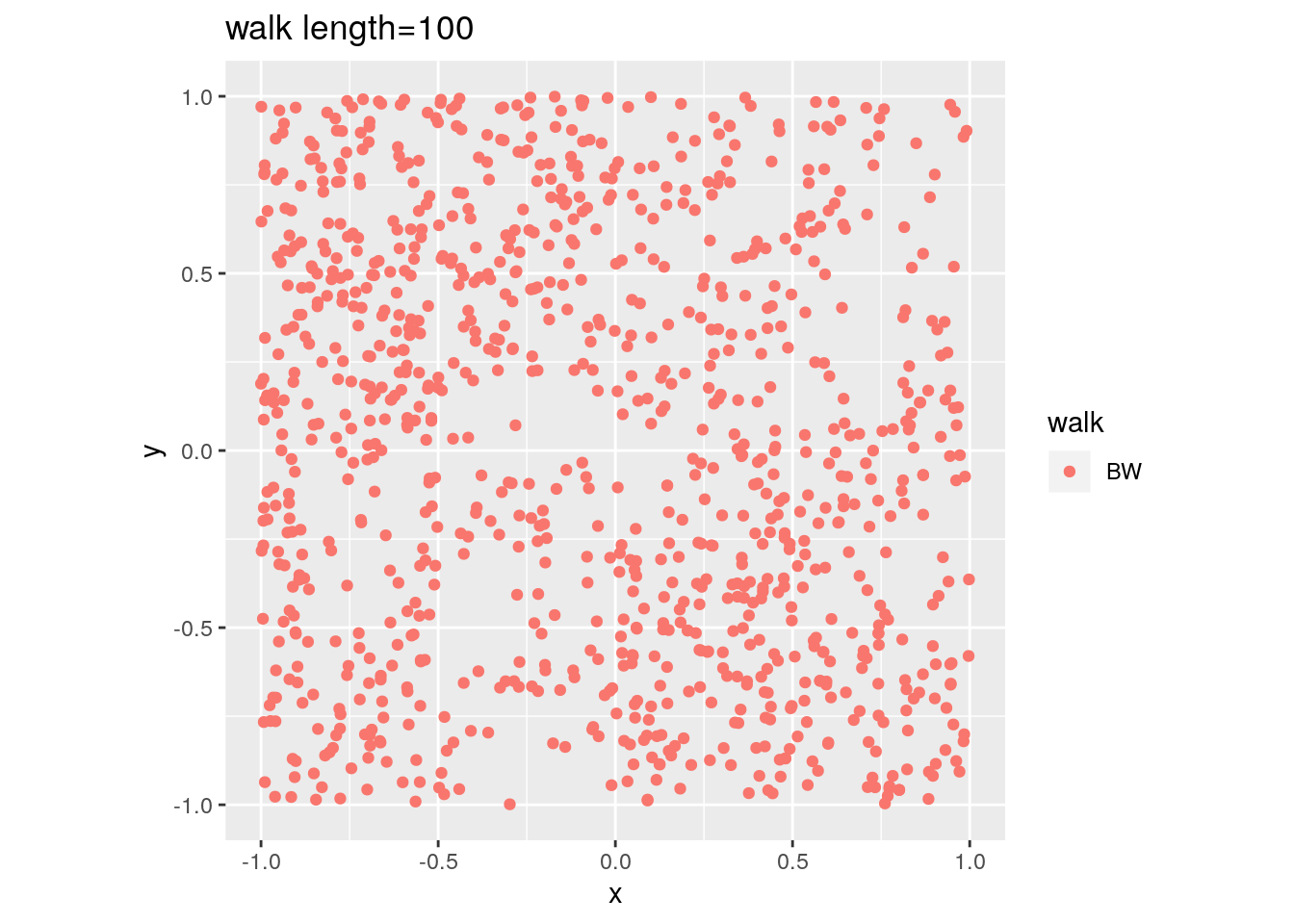
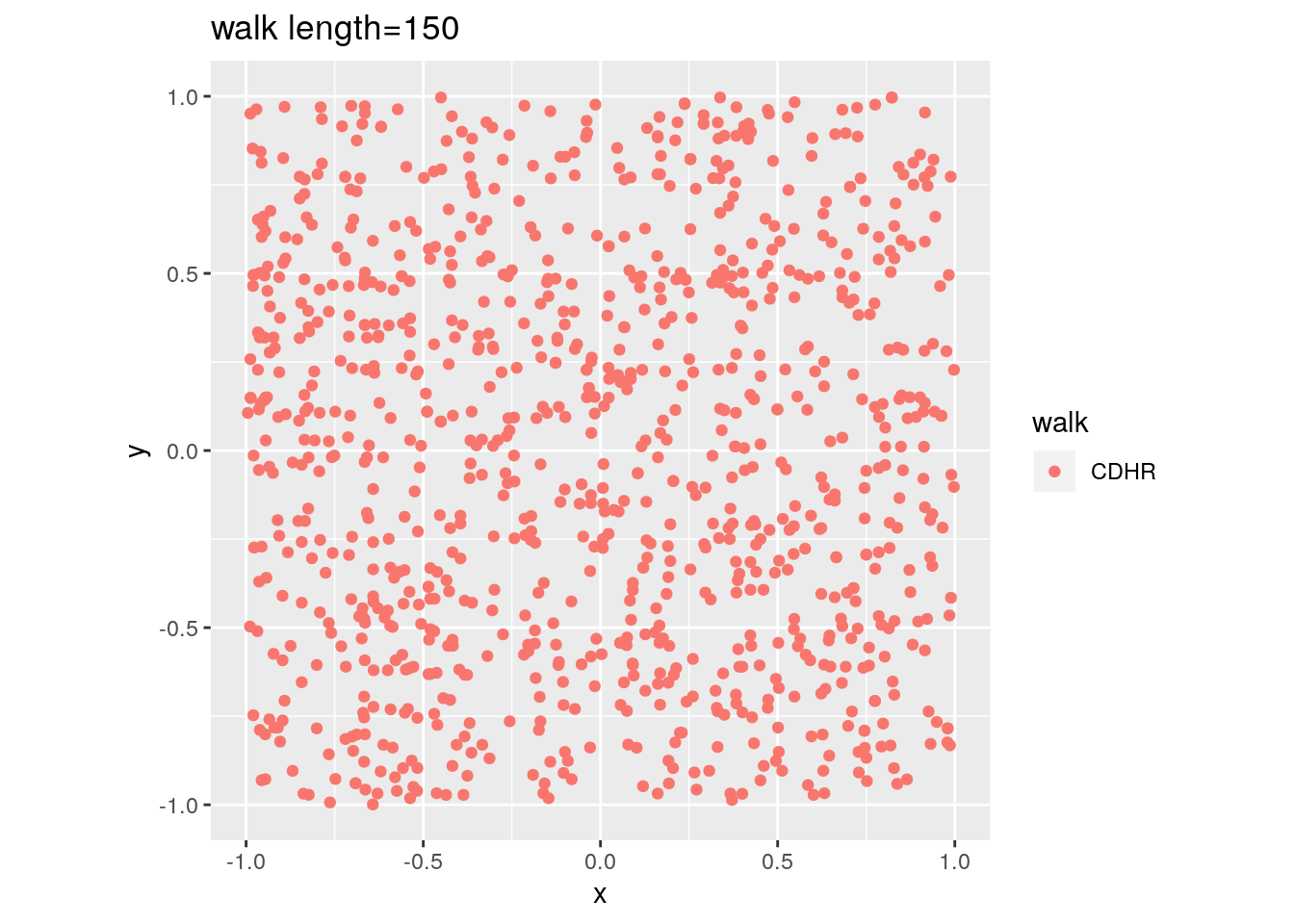
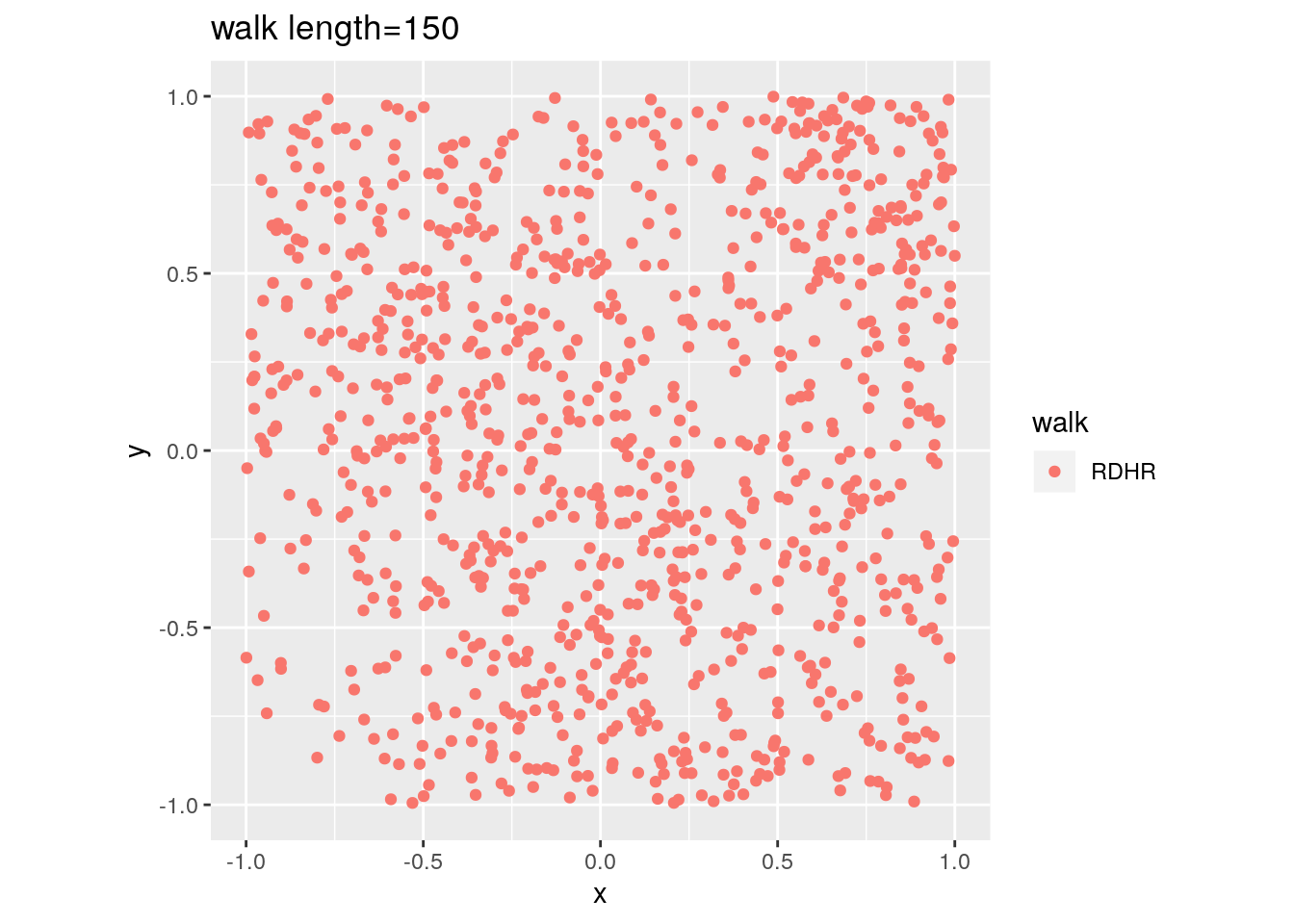
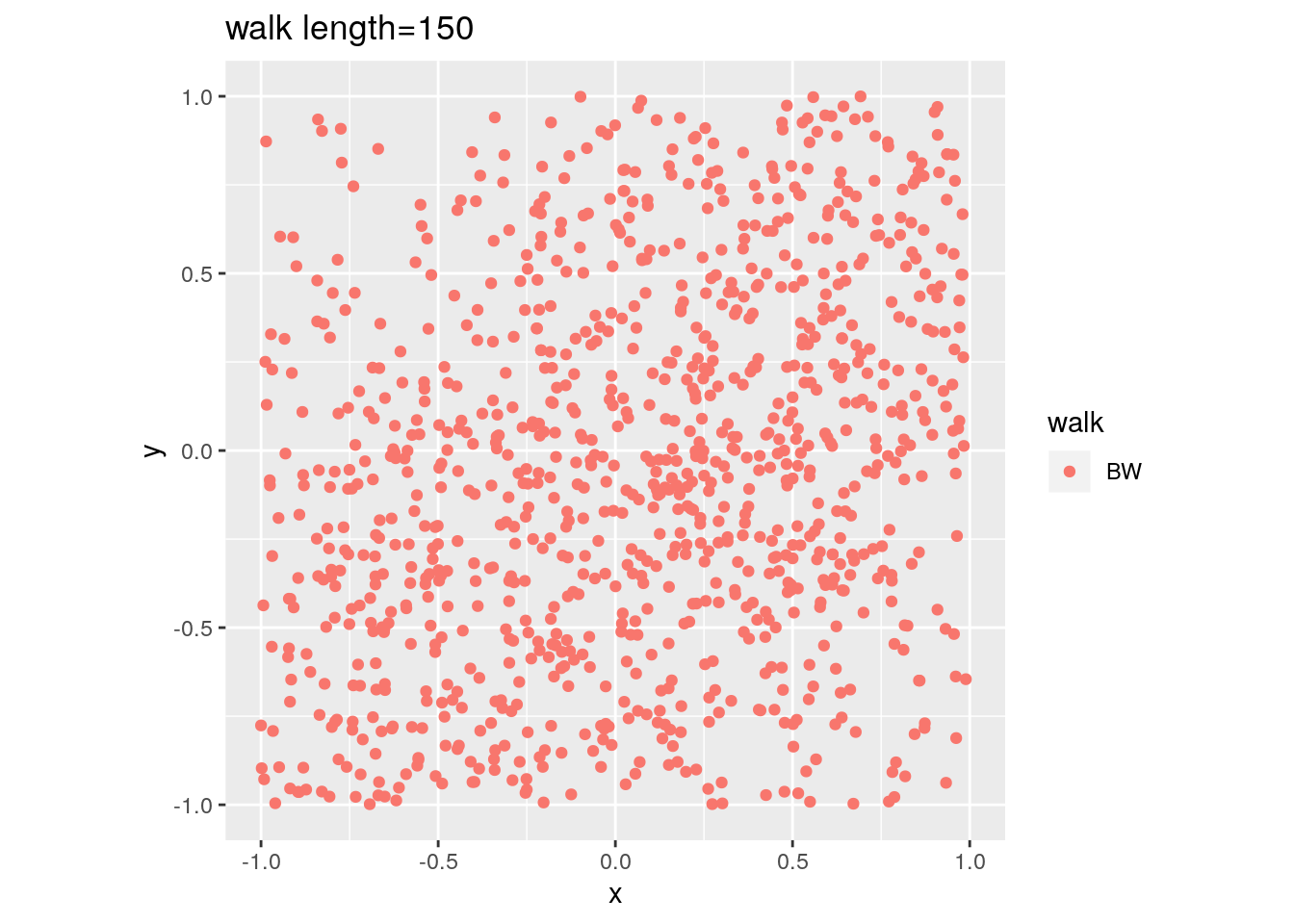
Volume estimation
Now let’s compute our first example. The volume of the 3-dimensional cube.
library(geometry)
PV <- GenCube(3,'V')
str(PV)
#P = GenRandVpoly(3, 6, body = 'cube')
tim1 <- system.time({ geom_values = convhulln(PV$V, options = 'FA') })
tim2 <- system.time({ vol2 = volume(PV) })
cat(sprintf("exact vol = %f\napprx vol = %f\nrelative error = %f\n",
geom_values$vol, vol2, abs(geom_values$vol-vol2)/geom_values$vol))
Now try a higher dimensional example. By setting the error parameter we can control the apporximation of the algorithm.
PH = GenCube(10,'H')
volumes <- list()
for (i in 1:10) {
# default parameters
volumes[[i]] <- volume(PH, error=1)
}
options(digits=10)
summary(as.numeric(volumes))
volumes <- list()
for (i in 1:10) {
volumes[[i]] <- volume(PH, error=0.5)
}
summary(as.numeric(volumes))
Deterministic algorithms for volume are limited to low dimensions (e.g. less than \(15\))
library(geometry)
P = GenRandVpoly(15, 30)
# this will return an error about memory allocation, i.e. the dimension is too high for qhull
tim1 <- system.time({ geom_values = convhulln(P$V, options = 'FA') })
#warning: this also takes a lot of time in v1.0.3
print(volume(P))
Volume of Birkhoff polytopes
We now continue with a more interesting example, the 10-th Birkhoff polytope. It is known from https://arxiv.org/pdf/math/0305332.pdf that its volume equals
\(\text{vol}(\mathcal{B}_{10}) = \frac{727291284016786420977508457990121862548823260052557333386607889}{828160860106766855125676318796872729344622463533089422677980721388055739956270293750883504892820848640000000}\)
obtained via massive parallel computation.
library(volesti)
P <- fileToMatrix('data/birk10.ine')
exact <- 727291284016786420977508457990121862548823260052557333386607889/828160860106766855125676318796872729344622463533089422677980721388055739956270293750883504892820848640000000
# warning the following will take around half an hour
#print(volume(P, Algo = 'CG'))
Compare our computed estimation with the “normalized” floating point version of \(\text{vol}(\mathcal{B}_{10})\)
n <- 10
vol_B10 <- 727291284016786420977508457990121862548823260052557333386607889/828160860106766855125676318796872729344622463533089422677980721388055739956270293750883504892820848640000000
print(vol_B10/(n^(n-1)))
Rounding
We generate skinny polytopes, in particular skinny cubes of the form \({x=(x_1,\dots,x_d)\ |\ x_1\leq 100, x_1\geq-100,x_i\leq 1,x_i\geq-1,x_i\in \mathbb{R}, \text{ for } i=2,\dots,d}\).
Our random walks perform poorly on those polytopes espacially as the dimension increases. Note that if we use the CDHR walk here is cheating since we take advanatage of the instance structure.
library(ggplot2)
P = GenSkinnyCube(2)
points1 = sample_points(P, WalkType = "CDHR", N=1000)
ggplot(data.frame(x = c(points1[1,]), y = c(points1[2,])), aes(x=x, y=y)) + geom_point() +labs(x =" ", y = " ")+coord_fixed(ylim = c(-10,10))
points1 = sample_points(P, WalkType = "RDHR", N=1000)
ggplot(data.frame(x = c(points1[1,]), y = c(points1[2,])), aes(x=x, y=y)) + geom_point() +labs(x =" ", y = " ")+coord_fixed(ylim = c(-10,10))
P = GenSkinnyCube(10)
points1 = sample_points(P, WalkType = "CDHR", N=1000)
ggplot(data.frame(x = c(points1[1,]), y = c(points1[2,])), aes(x=x, y=y)) + geom_point() +labs(x =" ", y = " ")+coord_fixed(xlim = c(-100,100), ylim = c(-10,10))
points1 = sample_points(P, WalkType = "RDHR", N=1000)
ggplot(data.frame(x = c(points1[1,]), y = c(points1[2,])), aes(x=x, y=y)) + geom_point() +labs(x =" ", y = " ")+coord_fixed(xlim = c(-100,100), ylim = c(-10,10))
P = GenSkinnyCube(100)
points1 = sample_points(P, WalkType = "RDHR", N=1000)
ggplot(data.frame(x = c(points1[1,]), y = c(points1[2,])), aes(x=x, y=y)) + geom_point() +labs(x =" ", y = " ")+coord_fixed(xlim = c(-100,100), ylim = c(-10,10))
Then we examine the problem of rounding by sampling in the original and then in the rounded polytope and look at the effect in volume computation.
library(ggplot2)
d <- 10
P = GenSkinnyCube(d)
points1 = sample_points(P, WalkType = "CDHR", N=1000)
ggplot(data.frame(x = c(points1[1,]), y = c(points1[2,])), aes(x=x, y=y)) + geom_point() +labs(x =" ", y = " ")+coord_fixed(ylim = c(-10,10))
P <- rand_rotate(P)$P
points1 = sample_points(P, WalkType = "RDHR", N=1000)
ggplot(data.frame(x = c(points1[1,]), y = c(points1[2,])), aes(x=x, y=y)) + geom_point() +labs(x =" ", y = " ")+coord_fixed()
exact <- 2^d*100
cat("exact volume = ", exact , "\n")
cat("volume estimation (no round) = ", volume(P, WalkType = "RDHR", rounding=FALSE), "\n")
cat("volume estimation (rounding) = ", volume(P, WalkType = "RDHR", rounding=TRUE), "\n")
# 1st step of rounding
res1 = round_polytope(P)
points2 = sample_points(res1$P, WalkType = "RDHR", N=1000)
ggplot(data.frame(x = c(points2[1,]), y = c(points2[2,])), aes(x=x, y=y)) + geom_point() +labs(x =" ", y = " ")+coord_fixed()
volesti <- volume(res1$P) * res1$round_value
cat("volume estimation (1st step) = ", volesti, " rel. error=", abs(exact-volesti)/exact,"\n")
# 2nd step of rounding
res2 = round_polytope(res1$P)
points2 = sample_points(res2$P, WalkType = "RDHR", N=1000)
ggplot(data.frame(x = c(points2[1,]), y = c(points2[2,])), aes(x=x, y=y)) + geom_point() +labs(x =" ", y = " ")+coord_fixed()
volesti <- volume(res2$P) * res1$round_value * res2$round_value
cat("volume estimation (2nd step) = ", volesti, " rel. error=", abs(exact-volesti)/exact,"\n")
# 3rd step of rounding
res3 = round_polytope(res2$P)
points2 = sample_points(res3$P, WalkType = "RDHR", N=1000)
ggplot(data.frame(x = c(points2[1,]), y = c(points2[2,])), aes(x=x, y=y)) + geom_point() +labs(x =" ", y = " ")+coord_fixed()
volesti <- volume(res3$P) * res1$round_value * res2$round_value * res3$round_value
cat("volume estimation (3rd step) = ", volesti, " rel. error=", abs(exact-volesti)/exact,"\n")
Integration
We can use sampling and volume estimation to estimate integrals over polyhedral domains. Below there is an example with a degree 2 polynomial over a 3-dimensional cube.
library(cubature) # load the package "cubature"
f <- function(x) { 2/3 * (2 * x[1]^2 + x[2] + x[3]) + 10 } # "x" is vector
adaptIntegrate(f, lowerLimit = c(-1, -1, -1), upperLimit = c(1, 1, 1))$integral
# Simple Monte Carlo integration
# https://en.wikipedia.org/wiki/Monte_Carlo_integration
P = GenCube(3, 'H')
num_of_points <- 10000
points1 <- sample_points(P, WalkType = "RDHR", walk_step = 100, N=num_of_points)
int<-0
for (i in 1:num_of_points){
int <- int + f(points1[,i])
}
V <- volume(P)
print(int*V/num_of_points)
Counting linear extensions
Let \(G= (V, E)\) be an acyclic digraph with \(V= [n] :={1,2, . . . , n}\). One might want to consider \(G\) as a representation of the partially ordered set (poset) \(V:i > j\) if and only if there is a directed path from node \(i\) to node \(j\).A permutation \(\pi\) of \([n]\) is called a linear extension of \(G\) (or the associated poset \(V\)) if \(\pi^{−1}(i)> \pi^{−1}(j)\) for every edge \(i\rightarrow j \in E\).
Let \(P_{LE}(G)\) be the polytope in \(\mathbb R^n\) defined by \(P_{LE}(G)\) \(={x\in \mathbb R^n\ |\ 1\geq x_i \geq 0 \text{ for all } i=1,2,\dots ,n}\) and \(x_i\geq x_j\) for all directed edges \(i\rightarrow j \in E\).
A well known result is that the number of linear extensions of \(G\) is \(vol(P)*n!\).
The following example from notes has \(9\) linear extensions. See also this paper for counting linear extensions in practice.
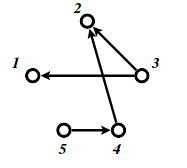
We can approximate this number by the following code.
A = matrix(c(-1,0,1,0,0,0,-1,1,0,0,0,-1,0,1,0,0,0,0,-1,1,1,0,0,0,0,0,1,0,0,0,0,0,1,0,0,0,0,0,1,0,0,0,0,0,1,-1,0,0,0,0,0,-1,0,0,0,0,0,-1,0,0,0,0,0,-1,0,0,0,0,0,-1), ncol=5, nrow=14, byrow=TRUE)
b = c(0,0,0,0,0,0,0,0,0,1,1,1,1,1)
P = Hpolytope$new(A, b)
volume(P,error=0.2)*factorial(5)
Financial modelling
For a specific set of assets in a stock market, portfolios are characterized by their return and their risk which is the variance of the portfolios’ returns (volatility). Copulas are approximations of the bivariate joint distribution of return and volatility.
#install.packages('plotly')
library('plotly')
MatReturns <- read.table("https://stanford.edu/class/ee103/data/returns.txt", sep=",")
MatReturns = MatReturns[-c(1,2),]
dates = as.character(MatReturns$V1)
MatReturns = as.matrix(MatReturns[,-c(1,54)])
MatReturns = matrix(as.numeric(MatReturns [,]),nrow = dim(MatReturns )[1], ncol = dim(MatReturns )[2], byrow = FALSE)
#starting_date = "2008-12-18" ##crisis period
#stopping_date = "2009-03-13"
starting_date = "2007-03-07" ##normal period
stopping_date = "2007-05-31"
row1 = which(dates %in% starting_date)
row2 = which(dates %in% stopping_date)
nassets = dim(MatReturns)[2]
W=row1:row2
compRet = rep(1,nassets)
for (j in 1:nassets) {
for (k in W) {
compRet[j] = compRet[j] * (1 + MatReturns[k, j])
}
compRet[j] = compRet[j] - 1
}
mass = copula2(h = compRet, E = cov(MatReturns[row1:row2,]), numSlices = 100, N=1000000)
plot_ly(z = ~mass) %>% add_surface(showscale=FALSE)